PyTorch 实现多分类任务总结
数据集处理
实验记录
在 Kaggle 网站上下载 Otto Group Product Classification Challenge 数据集,解压在 ./dataset/otto-group-product-classification-challenge 下
导入数据集并查看基本信息
导入库
1
2
3
4import os
import numpy as np
import pandas as pd设置 dataset 地址
1
2
3
4TRAIN_PATH = "./dataset/otto-group-product-classification-challenge/train.csv"
TEST_PATH = "./dataset/otto-group-product-classification-challenge/test.csv"
SAMPLE_SUBMISSION_PATH = "./dataset/otto-group-product-classification-challenge/sampleSubmission.csv"
PROCESSED_TRAIN_PATH = "./dataset/otto-group-product-classification-challenge/processed_train.csv"读取 training dataset
1
train_data = pd.read_csv(TRAIN_PATH, index_col=0)
显示 training dataset 信息
1
train_data.info()
1
2
3
4
5
6
7
8
9
10
11
12
13
14Output exceeds the size limit. Open the full output data in a text editor
<class 'pandas.core.frame.DataFrame'>
Int64Index: 61878 entries, 1 to 61878
Data columns (total 94 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 feat_1 61878 non-null int64
1 feat_2 61878 non-null int64
2 feat_3 61878 non-null int64
...
92 feat_93 61878 non-null int64
93 target 61878 non-null object
dtypes: int64(93), object(1)
memory usage: 44.8+ MB查看 training dataset 前几行
1
train_data.head()
![training dataset(before)]()
查找是否存在缺失值
1
train_data.isnull().sum()
1
2
3
4
5
6
7
8
9
10
11
12feat_1 0
feat_2 0
feat_3 0
feat_4 0
feat_5 0
..
feat_90 0
feat_91 0
feat_92 0
feat_93 0
target 0
Length: 94, dtype: int64读取 testing dataset
1
test_data = pd.read_csv(TEST_PATH, index_col=0)
显示 testing dataset 信息
1
test_data.info()
1
2
3
4
5
6
7
8
9
10
11
12
13
14Output exceeds the size limit. Open the full output data in a text editor
<class 'pandas.core.frame.DataFrame'>
Int64Index: 144368 entries, 1 to 144368
Data columns (total 93 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 feat_1 144368 non-null int64
1 feat_2 144368 non-null int64
2 feat_3 144368 non-null int64
...
91 feat_92 144368 non-null int64
92 feat_93 144368 non-null int64
dtypes: int64(93)
memory usage: 103.5 MB查看 testing dataset 前几行
1
test_data.head()
![testing dataset(before)]()
查找是否存在缺失值
1
test_data.isnull().sum()
1
2
3
4
5
6
7
8
9
10
11
12feat_1 0
feat_2 0
feat_3 0
feat_4 0
feat_5 0
..
feat_89 0
feat_90 0
feat_91 0
feat_92 0
feat_93 0
Length: 93, dtype: int64统计 target 列中的类别和数量
1
train_data['target'].value_counts()
1
2
3
4
5
6
7
8
9
10Class_2 16122
Class_6 14135
Class_8 8464
Class_3 8004
Class_9 4955
Class_7 2839
Class_5 2739
Class_4 2691
Class_1 1929
Name: target, dtype: int64数据处理
根据上面的信息,可以看到 training dataset 的特征为 int ,标签为 Classs_1 ~ Class_9 的字符串
现在需要将标签转换为 one-hot 格式
1
train_data = pd.get_dummies(train_data)
确认处理结果
1
train_data.head()
![training dataset(after)]()
1
train_data.info()
1
2
3
4
5<class 'pandas.core.frame.DataFrame'>
Int64Index: 61878 entries, 1 to 61878
Columns: 102 entries, feat_1 to target_Class_9
dtypes: int64(93), uint8(9)
memory usage: 44.9 MB1
train_data.notnull().sum()
1
2
3
4
5
6
7
8
9
10
11
12feat_1 61878
feat_2 61878
feat_3 61878
feat_4 61878
feat_5 61878
...
target_Class_5 61878
target_Class_6 61878
target_Class_7 61878
target_Class_8 61878
target_Class_9 61878
Length: 102, dtype: int64写入到 CSV 文件中
1
train_data.to_csv(PROCESSED_TRAIN_PATH, index=False)



回顾
pandas.isnull() 函数
可以以布尔类型返回各行各列是否存在缺失 加上 sum() 函数可以统计各列的缺失情况
参考网站
若尘公子 - #有空学04# pandas缺失数据查询
pandas - pandas.isnull
pandas.value_count() 函数
可以返回该列中数据种类及其数量
方便后续进行格式转换
参考网站
快乐的皮卡丘呦呦 - Pandas中查看列中数据的种类及个数 pandas - pandas.DataFrame.value_counts
pandas.get_dummies() 函数
pandas.get_dummies() 函数会将非数值型数据转换为 One-Hot 格式
在该数据集中即使不指定 columns 参数,也只会转换 target 一列
参考网页
ChaoFeiLi - 操作pandas某一列实现one-hot
pandas - pandas.get_dummies
pandas - pandas.get_dummies
模型训练
导入库
1 | import matplotlib.pyplot as plt |
准备数据集
1 | # 派生 CSV_Dataset 类 |
设计网络模型
1 | class Net(nn.Module): |
设计 Loss 和优化器
1 | criterion = torch.nn.CrossEntropyLoss() |
交叉熵损失函数
$$Loss = -\sum^n_{i=1} y_i \log y'_i$$
交叉熵损失函数通常用于多分类任务的损失函数
NLLLoss
NLLLoss 是将 Label 转换为 One-Hot 形式后与输出结果进行交叉熵计算
Torch.nn.CrossEntropyLoss() 函数
Torch.nn.CrossEntropyLoss() 函数是先将输出结果输入到 Softmax 层后取对数,再应用 NLLLoss
即 Torch.nn.CrossEntropyLoss() = LogSoftmax + NLLLoss
训练过程
1 | def train(epoch): |
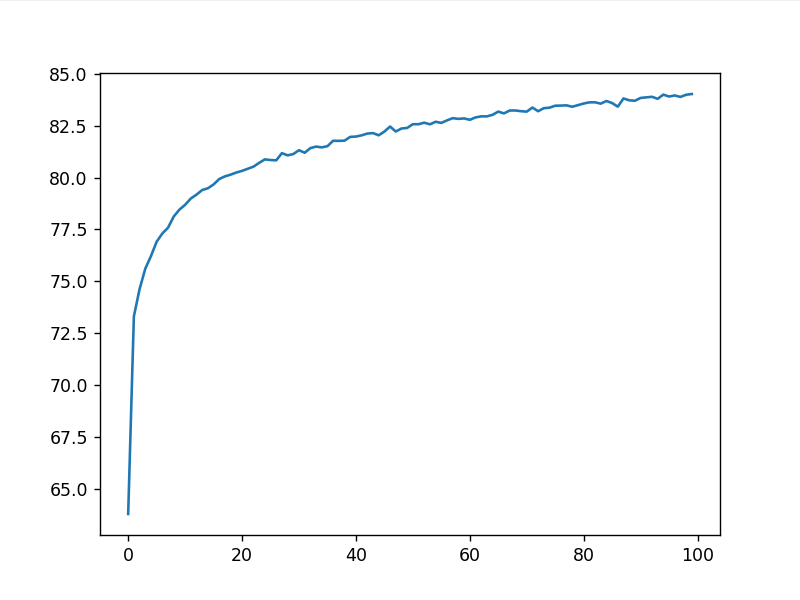
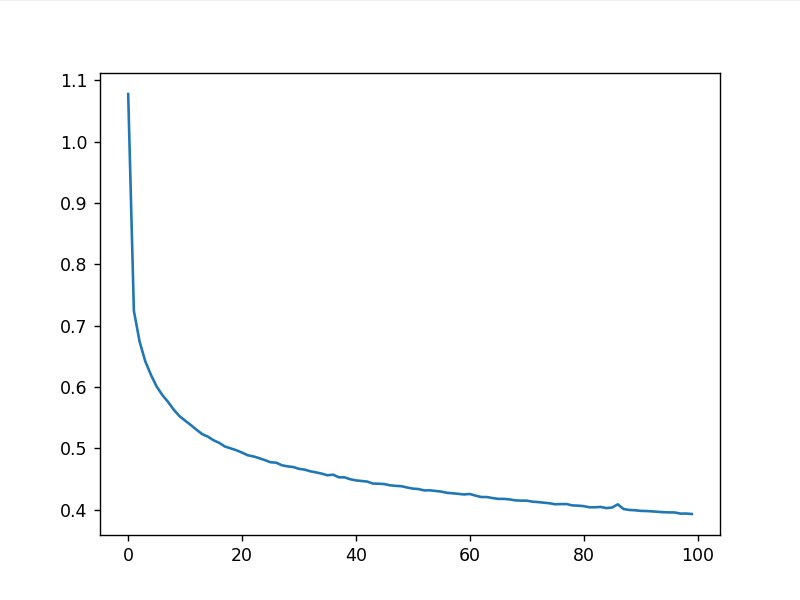
训练结果
Loss 随训练轮次变化
acc 随训练轮次变化