PyTorch 实现分类问题总结
数据集处理
实验记录
在 Kaggle 网站上下载 Titanic 数据集,解压在 ./dataset/Titanic 下
由于 Jupiter 可以实现数据的实时可视化,在此使用 Jupiter 进行数据集的观察与处理
新建
.ipynb文件后导入 Python 库1
2import os
import pandas as pd设置数据集的相对地址
1
2TRAIN_PATH = "./dataset/titanic/train.csv"
PROCESSED_TRAIN_PATH = "./dataset/titanic/processed_train.csv"读取并显示 train dataset 信息
1
2train_data = pd.read_csv(TRAIN_PATH)
train_data.info()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB可以看到 PassengerId 、 Name 、 Ticket 三列数据与是否生存无关,将其丢弃
1
2train_data = train_data.drop(['PassengerId', 'Name', 'Ticket'], axis=1)
train_data.info()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Sex 891 non-null object
3 Age 714 non-null float64
4 SibSp 891 non-null int64
5 Parch 891 non-null int64
6 Fare 891 non-null float64
7 Cabin 204 non-null object
8 Embarked 889 non-null object
dtypes: float64(2), int64(4), object(3)
memory usage: 62.8+ KBAge 数据缺失,现在使用均值进行补充
1
2
3avg_age = train_data['Age'].mean()
train_data['Age'] = train_data['Age'].fillna(avg_age)
train_data.info()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Sex 891 non-null object
3 Age 891 non-null float64
4 SibSp 891 non-null int64
5 Parch 891 non-null int64
6 Fare 891 non-null float64
7 Cabin 204 non-null object
8 Embarked 889 non-null object
dtypes: float64(2), int64(4), object(3)
memory usage: 62.8+ KB由于 Cabin 数据确实太多,将其丢弃
1
2train_data = train_data.drop(['Cabin'], axis=1)
train_data.info()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Sex 891 non-null object
3 Age 891 non-null float64
4 SibSp 891 non-null int64
5 Parch 891 non-null int64
6 Fare 891 non-null float64
7 Embarked 889 non-null object
dtypes: float64(2), int64(4), object(2)
memory usage: 55.8+ KB查看 Embarked 数据中的众数
1
train_data['Embarked'].value_counts()
1
2
3
4S 644
C 168
Q 77
Name: Embarked, dtype: int64使用众数进行补充缺失的数据
1
2train_data['Embarked'] = train_data['Embarked'].fillna('S')
train_data.info()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Sex 891 non-null object
3 Age 891 non-null float64
4 SibSp 891 non-null int64
5 Parch 891 non-null int64
6 Fare 891 non-null float64
7 Embarked 891 non-null object
dtypes: float64(2), int64(4), object(2)
memory usage: 55.8+ KB查看 Sex 数据的情况
1
train_data['Sex'].head()
1
2
3
4
5
60 male
1 female
2 female
3 female
4 male
Name: Sex, dtype: object将 Sex 数据的值映射成数值
1
2
3sex_2_dict = {"male": 0, "female":1}
train_data['Sex'] = train_data['Sex'].map(sex_2_dict)
train_data.info()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Sex 891 non-null int64
3 Age 891 non-null float64
4 SibSp 891 non-null int64
5 Parch 891 non-null int64
6 Fare 891 non-null float64
7 Embarked 891 non-null object
dtypes: float64(2), int64(4), object(1)
memory usage: 55.8+ KB查看 Embarked 数据的情况
1
train_data['Embarked'].head()
1
2
3
4
5
60 S
1 C
2 S
3 S
4 S
Name: Embarked, dtype: object将 Embarked 数据的值映射成数值
1
2
3embarked_2_dict = {"C": 0, "Q": 1, "S": 2}
train_data['Embarked'] = train_data['Embarked'].map(embarked_2_dict)
train_data.info()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Sex 891 non-null int64
3 Age 891 non-null float64
4 SibSp 891 non-null int64
5 Parch 891 non-null int64
6 Fare 891 non-null float64
7 Embarked 891 non-null int64
dtypes: float64(2), int64(6)
memory usage: 55.8 KB将处理好的数据集导出到文件夹中
1
train_data.to_csv(PROCESSED_TRAIN_PATH, index=False)
回顾
conda 安装 Jupiter 报错
打开 clash 后,用 conda 安装 Jupiter 报错
1 | CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/linux-64/current_repodata.json> |
错误出现原因
clash 代理影响 conda 与 conda 源的连接
解决方法1
在用户文件夹下的 .condarc 文件中添加代理端口
clash 的默认代理端口为 7890
1 | proxy_servers: |
但在后续的安装中依旧报错
1 | Retrieving notices: ...working... failed |
此解决方法无效
解决方法2
关闭 clash
参考网页
wielice - conda 配置本机代理
好事要发生 - An HTTP error occurred when trying to retrieve this URL. HTTP errors are often intermittent……
pandas.read_csv() 函数
从 CSV 文件中读取数据到 DataFrame
1 | pandas.read_csv(filepath_or_buffer, sep=NoDefault.no_default, |
部分重要参数解析
filepath_or_buffer
str ,路径对象或类文件对象
任何有效的字符串路径都可以接受
该字符串可以是一个 URL
有效的 URL 方案包括 http 、 ftp 、 s3 、 gs 和 file
sep
str ,默认为’,’
长于 1 个字符且与’ + ’不同的分隔符将被解释为正则表达式
delimiter
str ,与 sep 参数功能相同,但默认为 ‘None’
当 sep 参数与 delimiter 参数均不为 None 时,弹出错误信息
1
ValueError: Specified a sep and a delimiter; you can only specify one.
header
int 或 int 列表 或 None ,但默认为 ‘Infer’
指定表头在数据中的行数
- 当 header 参数为默认的 ‘Infer’ 且 names 参数为 None 时,等价于 header = 0 ,此时将读取数据的第一行作为表头/列名
- 当 header 参数为默认的 ‘Infer’ 且 names 参数不为 None 时,等价于 header = None ,此时将读取 names 参数作为表头/列名
- 当 header 参数为 int 时,将从整数对应的行号读取列名
- 当 header 参数为 int 列表时,将从列表对应的行号读取列名
- 当 skip_blank_lines 参数为 True 且 names 参数不为 None 时,这个参数会忽略注释行和空行,会从数据的第一行而不是文件的第一行开始计算行数并读取表头
names
array-like ,可选
以传入的参数作为表头
- 参数中不允许有重复的内容
- 当 header 参数为 int 或 int 列表且 names 参数不为 None 时,将从 header 参数对应的行号读取列名,然后根据 names 参数对表头进行替换
dtype
Type name 或 column → type 字典,可选,默认为 None
将数据以参数数据类型读取
skiprows
list-like 或 int 或 可调用对象 ,可选,默认为 None
当 skiprows 的参数为 int 或 列表 时,将跳过对应行号的数据,对余下数据进行读取
当 skiprows 的参数为 可调用对象(如函数) 时,函数会先遍历行索引,进行条件判断,然后跳过函数返回值为 True 的行号的数据,对余下数据进行读取
index_col
int 或 str 或 int / str 序列,可选,默认为 None
当 index_col 的参数为 int 或 str 时,将对应列号/列名用作数据的索引
当 index_col 的参数为 int / str 序列时,将使用 MultiIndex,将对应列号/列名用作数据的索引
参考网页
pandas - pandas.read_csv
用 Python 学机器学习 - 一文掌握 read_csv 函数
pandas.DataFrame.to_csv() 函数
将 DataFrame 写入 CSV 文件中
1 | DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', |
部分重要参数
path_or_buf
str 或 path object 或 file-like object 或 None ,默认为 None
- 当 path_or_buf 的参数不为 None 时,将把 DataFrame 写入对应路径/文件名中
- 当 path_or_buf 的参数为 None 时,将把 DataFrame 以字符串形式打印出来 如果传递的是一个非二进制文件对象,应该用newline=‘’打开,禁用通用换行。 如果传递的是二进制文件对象,模式可能需要包含一个’b’。
sep
str ,默认为 ‘,’
用于输出文件的字段分隔符。
sep 的参数要求长度为1的字符串
na_rep
str ,默认为 ‘ ’
用于转换 DataFrame 中的 NaN
header
bool or str 列表,默认为 True
当 header 的参数为 bool 时,将根据 header 的参数决定是否将数据的表头写入文件中
当 header 的参数为 str 列表 时,将把 header 的参数作为表头写入文件中。
index
bool ,默认为 True
用于决定是否将索引写入文件中
mode
str ,默认为 ‘w’
用于设置 Python 的写入模式
参考网页
pandas - pandas.DataFrame.to_csv
AI阿聪 - pd.read_csv() 和 pd.to_csv() 常用参数
quantLearner - pd.read_csv()||pd.to_csv() 索引问题 index
暴躁的猴子 - pd.to_csv详解
模型训练
按照课程将代码分为四部分
在此之前导入库
1 | import pandas as pd |
Prepare dataset
构建 Dataset ,完成 Dataloader
1 | class TitanicDataset(Dataset): |
Design model using Class
从 torch.nn.Module 继承构建模型
1 | class Model(nn.Module): |
Construct loss and optimizer
使用 PyTorch API 指定 Loss 函数和优化器
1 | criterion = nn.BCELoss(reduction="mean") |
Training cycle
完成前向传播,反向传播,更新权值
1 | acc_list = [] |
回顾
继承 Dataset 类初始化报错
1 | TypeError: object.__new__() takes exactly one argument (the type to instantiate) |
错误出现原因
发现是将子类的初始化函数名称写成了 _init_ 而非 __init__
子类继承时未重构初始化函数,在创建实例时不能进行初始化
解决方法
修改为 __init__ 后错误信息消失
参考网页
摩天仑 - Python 学习坑 —— init
读取数据时将索引作为数据读入
使用 pandas.read_csv() 函数读取数据时,将索引作为数据读入数据中的第一列
错误出现原因
在将处理后的数据写入 CSV 文件时将索引也一并写入,但从 CSV 文件中读取数据时未声明数据中包含有索引
解决方法1
将 DataFrame 数据写入 CSV 文件时使用 pandas.DataFrame.to_csv(PATH, index=False)
解决方法2
从 CSV 文件读取数据时使用 pandas.read_csv(PATH, index_col=0)
参考网页
hellocsz - read_csv 文件读写参数详解
从 DataFrame 中提取数据报错
代码
1 | self.x_data = torch.from_numpy(xy[:, 1:-1]) |
错误信息
1 | TypeError: '(slice(None, None, None), slice(1, -1, None))' is an invalid key |
错误出现原因
DataFrame 的切片操作仅支持 .loc 和 .iloc 函数
解决方法
使用 pandas.DataFrame.iloc() 函数
1 | self.x_data = torch.tensor(xy.iloc[:, 1:]) |
pandas.DataFrame.iloc() 中的范围是左开右闭的
参考网页
pandas - pandas.DataFrame.iloc
方如一 - iloc[ ]函数(Pandas库)
从 dataset 读取数据时报错
代码
1 | dataset = TitanicDataset("./dataset/titanic/processed_train.csv") |
错误信息
1 | RuntimeError: DataLoader worker (pid(s) 32708, 31720) exited unexpectedly |
错误出现原因
未知,据推测是多线程工作的支持不好,或者是多线程被某些特定程序杀掉了
解决方法
将 num_workers 参数设置为 0 (默认为 0 )
1 | train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True) |
参考网页
xiuxiuxiuxiul - Pytorch设置多线程进行dataloader时影响GPU运行
计算 Loss 时报错
模型代码
1 | class Model(nn.Module): |
计算 Loss 代码
1 | for epoch in range(100): |
错误信息
1 | ValueError: Using a target size (torch.Size([32])) that is different to the input size (torch.Size([32, 1])) is deprecated. Please ensure they have the same size. |
错误出现原因
模型输出结果 label_pred 为 [32, 1] ,而 labels 为 [32] ,二者的维度不匹配
解决方法
在前馈计算中加入 pandas.DataFrame.squeeze(-1) 将输出结果的最后一维压缩
1 | class Model(nn.Module): |
参考网页
发梦公主 - 深度学习过程的Python报错收集
pandas - pandas.DataFrame.squeeze
实验结果
1 | # ...... |
结果评价
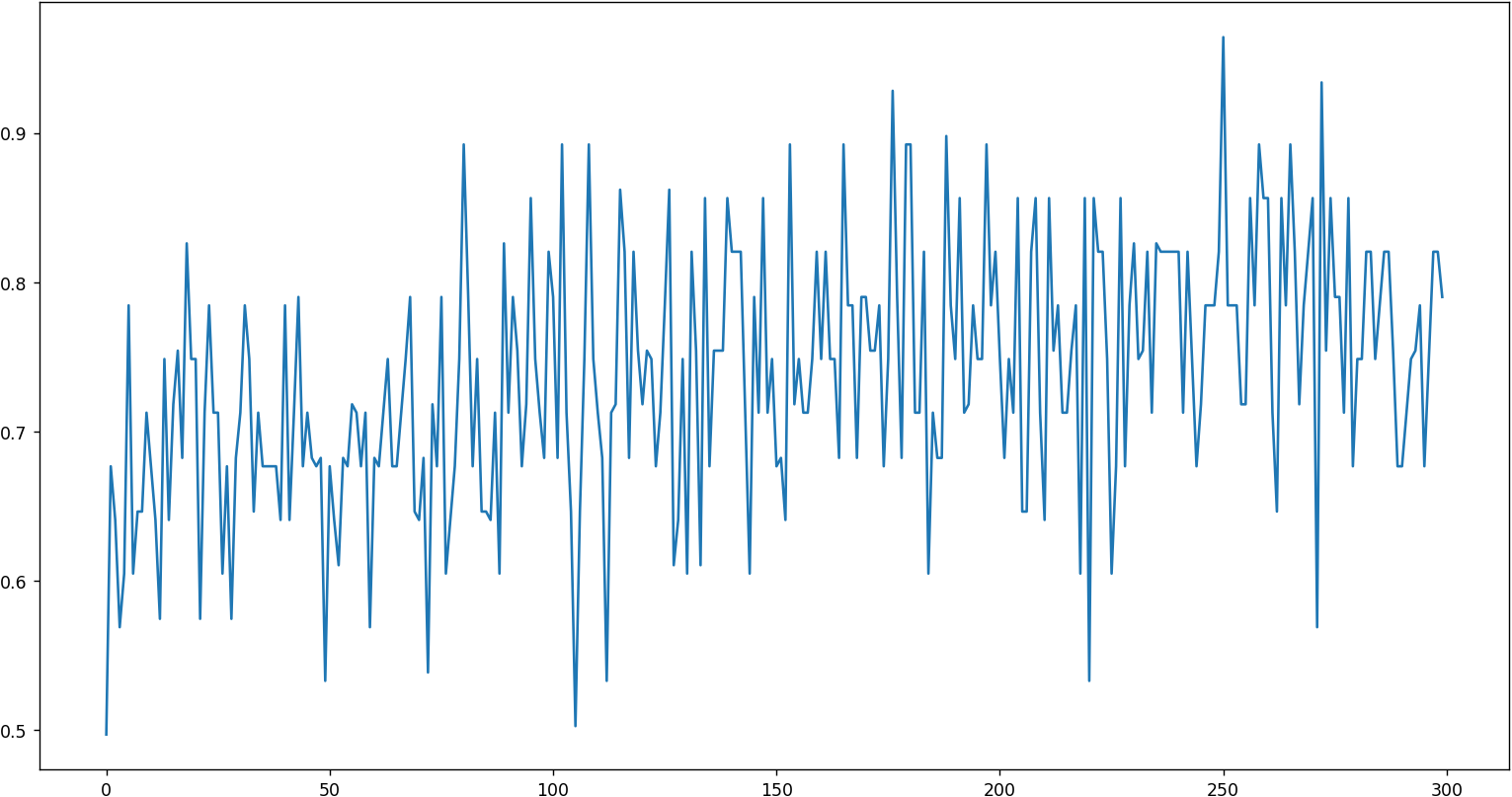
可以看到训练存在一定的效果,但并不明显,抖动明显
存在的问题
由于 loss 设置问题,不能直观显示 loss 随训练轮数变化
设计模型设计不够完善
本次实验中选取的特征只针对训练集,没有考虑测试集中数据的情况
在查看测试集中的数据后发现其中的 Fare 和 Age 数据缺失
可以将训练集和测试集中存在缺失数据的特征都去除
可以用训练集中的均值、众数填补测试集中的缺失项,但是这样将影响测试集,导致分类结果产生偏移
数据集中特征较少
后续改进
使用 K 折交叉校验法
重新设计训练模块
参考网页
刘二大人 - 《 PyTorch 深度学习实践》完结合集