PointNet 论文总结
作者提出了使用对称网络提取点云特征、局部特征与全局特征相结合的点云处理方法
Point Net 网络简单高效,具有很强的鲁棒性,能够抵抗异常点插入、部分点缺失和部分点抖动
Point Net 网络由 MLP 、全连接层和最大池化层组成
Abstract
PointNet 是直接使用点云进行三维目标分类、语义分割、场景语义解析的一种语义感知网络模型
PointNet 网络简单高效,面对微小扰动、点云缺失有很强的鲁棒性
Introduction
卷积不适用于点云数据
因为卷积结构要求输入数据高度规整,而点云是无序、不规整的
点云不适宜转换为其他形式进行语义感知
因为点云转换为其他形式进行处理时,会使得数据变得庞大
PointNet 网络的输入是三维坐标集合,输出是每点的标签/物体的标签
PointNet 网络能够学会利用稀疏的关键点来概括物体的形状,以判断物体的类别
Related Work
点云特征
现有的点云特征提取是针对特殊任务定制的,而找到最佳特征组合并非易事
三维数据的深度学习
Volumetric CNNs
在体素上应用卷积神经网络
受限于计算成本高和点云稀疏导致转换后的体素分辨率低
FPNN 和 Vote3D
提出了处理点云稀疏问题的办法
难以处理数量较大的点云
Multiview CNNs
将三维点云转换为二维图像,然后使用 CNN 进行分类
不能胜任语义分割、点云补全等任务
Feature-based DNNs
将三维点云转换为矢量,通过提取图形特征来进行分类
受限于特征提取能力,不能很好的完成任务
无序数据的深度学习
人们尚未探索基于无序点集的深度学习领域
而无序数据处理领域少数的硕果,也是关注于 NLP ,不适用于无序点集
Problem Statement
点云是三维坐标几何
对于物体分类任务,网络输出的结果应该是对 k 类的 k 个分数
对于语义分割任务,网络输出的结果应该是 n 个点对 m 类的 n * m 个分数
Deep Learning on Point Sets
点集的特性
无序性
点集是无序且不规整的,因此网络模型需要使用对称函数来提取特征
对称函数:无论输入顺序如何变化,输出结果保持不变
联系性
点集中的每个点不适孤立存在的,都是与周围的点联系的
因此网络模型要能够从附近点捕捉到局部结构,也能将局部特征和全局特征结合起来
变换不变性
点集在刚性变换后不会改变其语义标签
因此输入刚性变换后的点集,网络模型的输出应该保持不变
因此需要设计对准网络来提取点集特征
Point Net 的结构
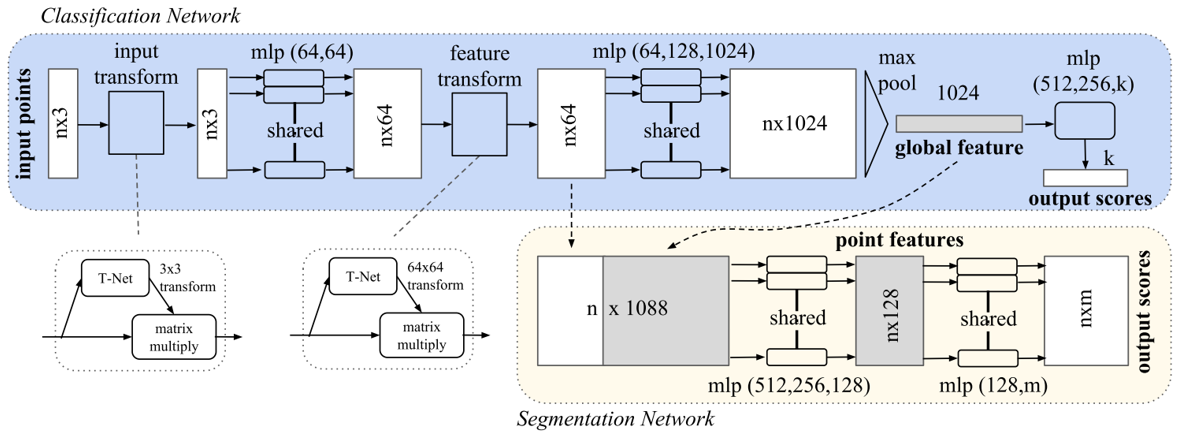
Point Net 网络具有三大关键组成:
- 使用最大池化层作为对称函数从点云中提取信息
- 局部特征与全局特征的结合机制
- 使用对准网络对齐输入点集及其特征
针对无序输入的对称函数
对于无序序列,有以下三种解决方法:
按特定顺序对序列进行排序
但是在高维空间,很难找到一种稳定可靠的排列方式
而且实验证明排序对结果提升不大
进行数据增强后输入给 RNN
但是 RNN 难以处理大量数据
使用对称函数来提取点集中的特征
通过集合中的转换元素应用对称函数来近似定义在点集上的对称函数
Point Net 网络采用该种方法
f({x1, ..., xn}) ≈ g(h(x1), ..., h(xn))
$$f:{ 2^{ \mathbb{R} } }^N \to \mathbb{R}, h:{ \mathbb{R} }^N \to { \mathbb{R} }^K, g:\underbrace{ {\mathbb{R} }^K \times \cdots \times {\mathbb{R} }^K }_{n} \to \mathbb{R}$$
在具体实现中,使用 MLP 来近似 h ,用单变量函数和最大池化函数来近似 g
局部特征和全局特征相结合
对称函数输出的是描述输入点集全局特征的一个向量
要实现点云分割需要结合局部特征和全局特征
Point Net 网络将全局特征和每个点的特征连接起来再提取每个点新的特征
对准网络
对点云进行处理需要保证输入点集进行刚性变换后其语义标签不变
一种解决方案是在特征提取前将所有输入点集对齐到一个典型空间
Point Net 网络通过一个微型网络( T-Net )预测一个矩阵,将该矩阵与输入坐标相乘实现变换
T-Net 也可以应用在特征空间的对齐,但是由于维度大,矩阵不好优化,需要加以约束,使得矩阵接近正交矩阵
Lreg = ||I − AAT||F2
理论分析
普遍近似
Point Net 网络具有对连续聚合函数普遍近似的能力,能够抵抗微小扰动
当最大池化层有足够多神经元,即式(1)中 K 足够大时, f 可以被任意近似
在最坏情况下, Point Net 网络 可以将空间划分为相同大小的体素,学习将点云转换为体积表示
瓶颈维度和稳定性
Point Net 网络的表现收到最大池化层维度的影响,即式(1)中 K
输入点集中的微小扰动不会影响 Point Net 网络的输出
Point Net 网络输出的结果实际上由点集中的部分点集决定,而该部分点集由式(1)中 K 决定
该部分点集 Cs 被称为关键点集,式(1)中 K 被称为瓶颈维度,而最大可能的点集 Ns 被称为上限点集
关键点集实际上形成了一个物体的骨架
Experiment
应用
物体分类
数据集:ModelNet40
数据构成:12311 个 CAD 模型,40 类物体,4:1 划分训练集和测试集
评价指标:准确率
数据预处理:对网格进行均匀采样后转换为单一球体,即转换为点云
实际项目中的数据预处理使用 RealityCapture 软件完成
数据增强:沿上轴随机旋转后通过高斯噪声对每个点位置进行抖动
结果:速度很快,分类准确率很高,但略逊于基于多视图的 MV CNN
分析:网络只有全连接层和最大池化层, CAD 模型转换为点云时损失了几何细节
物体语义分割
完整点云实验
数据集: ShapeNet part data set
数据构成:16881 个 CAD 模型,16 类物体,每个物体含有 2 ~ 5 个部件,共有50 类部件
评价指标: mIoU
结果:比大多数现有方法 mIoU 更高
不完整点云实验
数据集: ShapeNet part data set
数据处理:用 Blensor Kinect Simulator 从六个随机视点生成不完整的点云
结果:相较完整的点云,平均 IoU 只损失了 5.3%
场景语义分割
数据集: Stanford 3D semantic parsing data set
数据构成:271 个房间扫描的点云,包含 13 类物体
特殊处理:将房间划分为 1 m * 1 m 的区块,训练时在每个区块随机抽取4096个点
结果:明显优于使用定制的点云特征提取方法
场景中物体检测
结果:明显优于基于滑动形状法的 SVM
结构设计分析
对称函数间的比较
对比最大池化、平均池化和基于注意力的加权和
基于注意力的加权和:从每个点特征预测权值,归一化后计算与特征的加权和
最大池化的效果最好
输入转换和特征转换的有效性
使用 T-Net 进行转换使得性能提升 0.8%
Point Net 网络的鲁棒性
当 50% 的点缺失时,准确率只下降约 3%
当 20% 的点是离群的异常点时,准确率仍高于 80%
当高斯噪声使得点云抖动时,准确率依旧保持得很好
Point Net 网络结果可视化
关键点集 Cs 概括了物体形状的骨架
时空复杂度分析
Point Net 网络比 MVCNN 和 3D CNN 计算成本要低
Point Net 网络在 TensorFlow 上使用 1080X GPU 每秒可以处理 1000K 个点,完成 1K 个物体的分类或 2 个房间内的场景语义分割
Conclusion
Point Net 网络直接使用点云完成物体分类、语义分割和场景语义解析,且获得了很好的结果
补充
Point Net 模型的激活函数均使用 ReLu 函数
在进行点云分类时,在最后的 MLP 中加入了 Dropout 层
问题与解答
如何将全局特征和局部特征连接在一起?
1
2global_feat_expand = tf.tile(global_feat, [1, num_point, 1, 1])
concat_feat = tf.concat(3, [point_feat, global_feat_expand])使用
tf.tile(input, multiples, name=None)将全局特征复制拓展,使用tf.concat([tensor1, tensor2], axis)与局部特征拼接起来tf.tile(input, multiples, name=None)是将 input 各维度对应 multiples 参数复制multiples 参数维度必须 input 维度一致,表示在第几维上复制几次
multiples = [1, num_point, 1, 1]表示在第二维上复制 num_point 次tf.concat([tensor1, tensor2], axis)是将 tensor1 和 tensor2 在 axis 维度上拼接起来变量 Shape point_feat [None, num_point, 1, 64] global_feat [None, 1, 1, 1024] global_feat_expand [None, num_point, 1, 1024] concat_feat [None, num_point, 1, 1088] T-Net 网络内部是怎样的?
处理 Shape Input [None, num_point, 3, 1] 1*3卷积核-64 [None, num_point, 1, 64] conv1-128 [None, num_point, 1, 128] conv1-1024 [None, num_point, 1, 1024] Max Pooling [None, 1, 1, 1024] Reshape [None, 1024] FC-512 [None, 512] FC-256 [None, 256] MLP [None, 1, 9] Reshape [None, 3, 3] Output [None, 3, 3] 使用 T-Net 对数据进行转换可以理解为将数据进行矫正,对齐到到统一视角
为什么使用 Shared MLP ?
和普通 MLP 一样,都是实现特征提取
但是由于每个点的权重共享,可以节约大量参数
如何对点集应用 Shared MLP ?
实现时,使用 conv1,即使用 1 * 1 的卷积核进行卷积
模型的 Loss 如何计算?
classify_loss + mat_diff_loss * reg_weight平均多分类稀疏 softmax 交叉熵 + T-Net 产生预测矩阵的约束(式(2)) * 权重(默认为0.001)